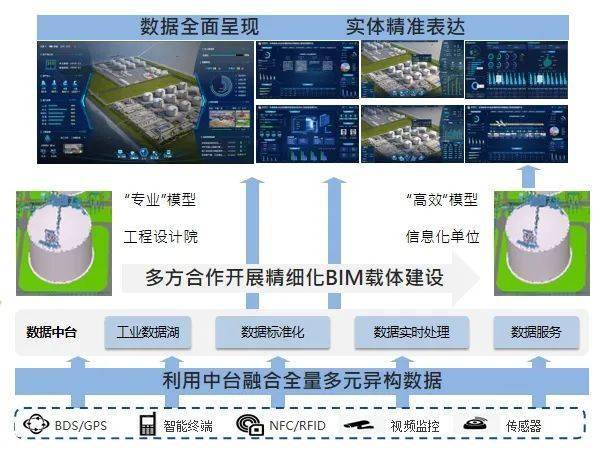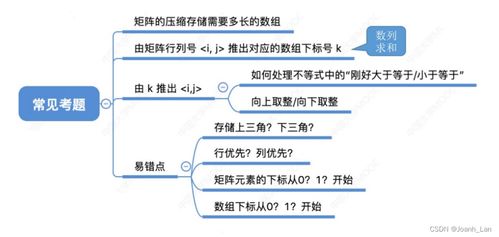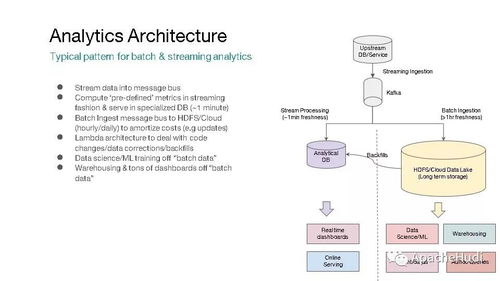
在数据驱动的时代,企业面临着处理海量数据并从中快速提取价值的巨大挑战。传统的数据架构通常将批处理与流处理割裂,导致数据孤岛、处理延迟高、维护成本巨大以及数据一致性难以保证。Apache Hudi(Hadoop Upserts Deletes and Incrementals)应运而生,作为一个开源的数据存储框架,它旨在统一批处理和近实时分析的数据处理范式,为现代数据湖提供高效、可靠的数据存储与服务能力。
核心价值:统一的数据处理层
Apache Hudi的核心设计理念是构建一个统一的数据处理层。它通过在分布式文件系统(如HDFS或云存储)之上引入表格式抽象,原生支持高效的记录级更新、删除操作以及增量数据查询。这意味着:
- 批流融合:传统上,批处理作业(如每天一次的ETL)和流处理作业(如实时事件处理)使用不同的技术和存储,导致数据冗余和同步复杂性。Hudi通过其“增量处理”模型,使得流式作业可以持续地将数据写入Hudi表,而批处理作业可以随时读取包含最新更新的完整数据集或特定时间范围内的增量数据。两者共享同一套存储和表结构,实现了真正的批流一体。
- 近实时分析:Hudi支持低至几分钟的数据落地延迟。通过其“写时合并”(Merge On Read)和“读时合并”(Copy On Write)两种表类型,用户可以在数据新鲜度与查询性能之间做出灵活权衡。例如,
Merge On Read表允许实时数据快速写入日志文件,后台再异步合并到列式存储文件中,从而实现对新数据的近实时查询。
关键技术与数据处理能力
Hudi通过一系列关键技术赋能高效的数据处理与存储服务:
- 事务性保证:提供ACID事务支持,确保在并发读写场景下的数据一致性。每一次提交都生成一个全局有序的时间轴,记录了表的所有变化,这是实现增量拉取和时间旅行查询的基础。
- 高效的更新与删除:直接支持主键级别的
UPSERT(插入/更新)和DELETE操作,无需重写整个分区或表。这极大地简化了变更数据捕获(CDC)场景、数据修正和数据合规(如GDPR删除请求)的实现。
- 自动文件管理:通过自动压缩(将小文件合并为更大、查询高效的文件)、清理(清除旧版本数据以节省存储)和聚类(优化文件布局)等后台服务,自动维护存储的健康状态和查询性能,降低了运维负担。
- 增量查询管道:基于其强大的时间轴元数据,Hudi能够精确地提取自某个时刻以来发生变化的数据。这使得构建高效的增量ETL管道变得异常简单,下游系统(如数据仓库、指标系统)只需消费增量数据,而非全量扫描,节省了大量计算资源。
作为数据存储服务的优势
在数据存储服务层面,Apache Hudi带来了范式转变:
- 服务化数据湖:它将原始的数据湖存储(通常是文件集合)转变为具有数据库式语义(增删改查、事务、索引)的“服务化”表。数据工程师和科学家可以像操作数据库表一样与之交互。
- 多引擎兼容:Hudi与主流数据处理引擎深度集成,包括Apache Spark、Flink、Trino/Presto、Hive等。这意味着计算引擎可以各司其职(Spark/Flink用于写入和ETL,Trino用于交互式查询),但都基于同一份Hudi存储,确保了数据的单一可信源。
- 提升数据新鲜度与效率:通过统一存储,数据从产生到可用于分析的时间被大幅缩短。增量处理模式减少了不必要的数据重复计算和移动,提升了整体数据处理效率,降低了成本。
典型应用场景
- 实时数据仓库:将来自业务数据库的CDC日志、应用日志和实时事件流近实时地摄入Hudi表,为BI和报表系统提供新鲜、统一的数据底座。
- 机器学习特征库:为特征工程提供支持频繁更新的特征存储,确保训练和推理使用的特征数据是最新且一致的。
- 增量ETL与数据管道:简化从操作型数据库到分析型系统的数据同步流程,构建高效、可靠的增量数据管道。
- 交互式查询服务:基于Hudi表提供对最新数据(包括刚更新或删除的记录)的低延迟查询能力。
###
Apache Hudi不仅仅是一个存储格式,更是一个旨在解决数据湖中数据管理痛点的综合性平台。它通过统一批处理和近实时分析的数据存储与服务层,实现了数据处理的简化和性能的飞跃。在构建现代化、高效且易于维护的数据架构时,Hudi为处理快速变化的海量数据提供了一个强大而灵活的解决方案,正成为企业解锁数据实时价值的关键基石。