MySQL作为当今最流行的关系型数据库之一,其高级特性的掌握对于数据库性能优化至关重要。本文将围绕索引的语法与原理、以及数据处理与存储服务两大主题展开深入探讨。
一、索引语法及索引的原理
索引是数据库中用于加速数据检索的数据结构,类似于书籍的目录,能够快速定位到所需数据,避免全表扫描,显著提升查询效率。
1. 索引的语法
在MySQL中,索引的创建、查看、修改和删除操作都有相应的SQL语法支持。
- 创建索引:可以在创建表时定义索引,也可以在已有表上添加索引。
示例:
`sql
-- 创建表时定义索引
CREATE TABLE users (
id INT PRIMARY KEY,
username VARCHAR(50),
email VARCHAR(100),
INDEX idxusername (username), -- 创建普通索引
UNIQUE INDEX idxemail (email) -- 创建唯一索引
);
-- 在已有表上添加索引
CREATE INDEX idxusername ON users(username);
ALTER TABLE users ADD INDEX idxemail(email);
`
- 查看索引:使用
SHOW INDEX FROM table_name;可以查看指定表的所有索引信息。 - 删除索引:使用
DROP INDEX index<em>name ON table</em>name;或ALTER TABLE table<em>name DROP INDEX index</em>name;删除索引。
2. 索引的原理
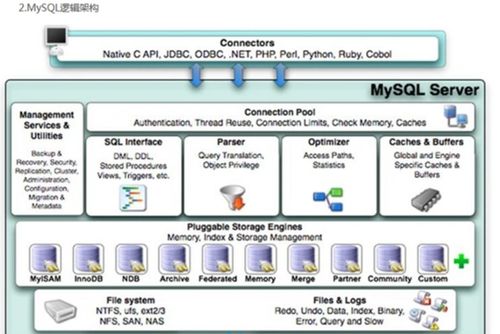
索引的工作原理基于高效的数据结构,主要是B+树(InnoDB存储引擎的默认索引结构)。
- B+树结构:B+树是一种多路平衡查找树,其特点包括:所有数据都存储在叶子节点,叶子节点之间通过指针相连形成有序链表,非叶子节点仅存储键值和子节点指针。这种结构使得范围查询和顺序访问效率极高。
- 索引类型:MySQL支持多种索引类型,包括主键索引(PRIMARY KEY)、唯一索引(UNIQUE)、普通索引(INDEX)、全文索引(FULLTEXT)和空间索引(SPATIAL)。每种索引适用于不同的场景。
- 索引的代价:虽然索引能加速查询,但也会带来额外的存储空间开销,并可能降低数据插入、更新和删除的速度,因为索引结构需要维护。因此,索引的创建需权衡利弊,避免过度索引。
二、数据处理和存储服务
MySQL不仅提供数据存储功能,还通过其数据处理和存储服务确保数据的完整性、一致性和高可用性。
- 数据处理
- 事务处理:MySQL支持ACID(原子性、一致性、隔离性、持久性)事务,通过InnoDB等存储引擎实现。事务确保了数据库操作的可靠性,特别是在并发环境下。
- 锁机制:MySQL通过锁机制管理并发访问,包括表锁、行锁等。合理的锁策略可以避免脏读、不可重复读和幻读等问题。
- 查询优化:MySQL的查询优化器会根据索引、表统计信息等自动选择最优执行计划。通过EXPLAIN命令可以分析查询执行过程,进一步优化SQL语句。
- 存储服务
- 存储引擎:MySQL支持多种存储引擎,如InnoDB、MyISAM、Memory等。InnoDB是默认引擎,支持事务和行级锁,适用于大多数应用场景;MyISAM适用于读密集且不需要事务的场景。
- 数据持久化:通过日志文件(如redo log、binlog)确保数据持久化。redo log用于崩溃恢复,binlog用于主从复制和数据恢复。
- 高可用与扩展:MySQL通过主从复制、读写分离、分库分表等技术实现高可用和水平扩展。例如,主从复制可以将数据同步到多个从服务器,提升读取性能和数据安全性。
深入理解MySQL的索引语法与原理,能够帮助我们设计高效的数据库结构;而掌握其数据处理与存储服务,则能确保系统在复杂场景下的稳定运行。在实际应用中,应根据业务需求合理使用索引,并选择合适的存储引擎和架构策略,以充分发挥MySQL的强大功能。