在当今的软件开发和运维实践中,监控与调优是保障系统稳定高效运行的关键环节。本文将系统性地探讨两个重要主题:如何在本地开发环境中查看和分析JVM的垃圾回收(GC)日志以优化应用性能,以及如何使用ELK技术栈(Elasticsearch、Logstash、Kibana)构建一个能够处理TB级别日志数据的监控系统,并涵盖数据处理与存储服务的相关设计思路。
一、本地运行中如何查看与分析GC日志
GC日志是诊断JVM内存问题、优化垃圾回收性能的重要依据。在本地开发或测试环境开启并查看GC日志,通常只需在JVM启动参数中进行配置。
1. 开启GC日志记录
* 对于JDK 8及之前的版本,常用的启动参数如下:
`bash
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:
`
-Xloggc 用于指定GC日志文件的输出路径。
* 对于JDK 9及更高版本,推荐使用统一的JVM日志框架,参数更为简洁强大:
`bash
-Xlog:gc*,gc+age=trace,safepoint:file=
`
此命令可以输出详细的GC信息,并支持日志轮转(保留5个文件,每个最大10MB)。
- 查看与分析GC日志
- 直接查看:对于简单的日志,可以直接使用文本编辑器或命令行工具(如
tail -f)查看实时输出的日志,关注Full GC的频率和持续时间。
- 使用分析工具:对于复杂的性能分析,推荐将日志文件导入可视化工具,它们能更直观地展示GC事件、内存变化趋势和暂停时间。
- GCeasy (https://gceasy.io/):一个在线的免费GC日志分析器,上传日志文件即可获得详尽的分析报告和可视化图表。
- GCViewer:一个开源的离线分析工具,可以从GitHub获取。
- JVM内置工具:如
jstat命令可以实时监控GC情况,但不如日志分析全面。
通过分析GC日志,可以定位是否存在频繁的Full GC、Young GC暂停时间过长、内存泄漏等问题,进而调整堆大小(-Xms, -Xmx)、新生代与老年代比例(-XX:NewRatio)或选择合适的垃圾收集器(如G1、ZGC)来优化应用。
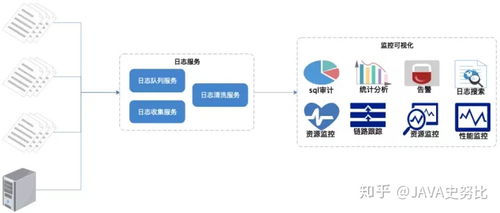
二、使用ELK搭建TB级日志监控系统:数据处理与存储服务设计
当系统规模扩大到生产环境,每日产生TB级的日志时,一个集中、可扩展的日志监控系统至关重要。ELK Stack是目前最流行的解决方案之一。
- 核心组件与架构
- Elasticsearch:负责日志数据的分布式存储、索引和搜索。它是系统的核心存储与计算引擎。
- Logstash:负责日志的收集、过滤、转换和输出。它可以从多种来源(文件、Kafka、Redis等)摄取数据,进行解析(如解析JSON、分割文本)后发送到Elasticsearch。
- Kibana:提供数据可视化界面,用于日志查询、仪表盘制作和监控告警。
- 扩展组件:在TB级场景下,通常会在日志生产端和Logstash之间引入 Beats(轻量级数据采集器,如Filebeat)和 消息队列(如Kafka或Redis),以解耦、缓冲并提高可靠性。
- TB级系统搭建与优化要点
- 集群化部署:所有组件都应集群化部署,避免单点故障。
- Elasticsearch集群:根据数据量、查询负载和可用性要求,规划足够数量的主节点、数据节点和协调节点。TB级数据通常需要至少3个主节点和多个数据节点。
- Logstash集群:部署多个Logstash实例进行负载均衡。
* 引入消息队列(Kafka):
架构变为:应用日志 -> Filebeat -> Kafka -> Logstash集群 -> Elasticsearch集群。
Kafka能应对日志洪峰,保证数据不丢失,并允许下游消费者(Logstash)按自身处理能力消费数据。
- Elasticsearch数据处理与存储优化:
- 索引设计:采用基于时间的索引策略(如
logs-app-2024-08-01),便于按时间范围管理和过期删除数据。使用索引模板统一设置映射和分片数。
- 分片与副本:合理设置索引的主分片数(影响分布式处理能力)和副本数(影响数据可靠性和读性能)。单个分片大小建议在30GB-50GB之间。
- 冷热数据分层:使用SSD存储热数据(近期高频查询),使用大容量HDD存储温冷数据(历史低频查询),通过Elasticsearch的索引生命周期管理(ILM)策略自动转移。
- 数据预处理:在Logstash或Elasticsearch Ingest Node中,尽可能地对日志进行结构化解析(如提取IP、时间戳、错误级别),避免在原始文本上查询,大幅提升查询效率。
- 性能与稳定性:
- 为Elasticsearch数据节点配置充足的内存(堆内存不超过31GB,预留一半内存给操作系统文件缓存)。
- 监控集群健康状态、节点负载、磁盘使用率和查询延迟。
- 设置索引的滚动(Rollover)和压缩(Force Merge)策略。
- 利用Kibana的告警功能或集成第三方告警系统(如Prometheus Alertmanager)实现异常监控。
3. 数据处理与存储服务
在广义的日志监控系统中,“数据处理与存储服务”可能超出ELK本身,涉及更下游的环节:
- 长期归档:对于需要合规性长期保存的日志,可以定期将Elasticsearch中的冷索引快照(Snapshot)备份到对象存储(如AWS S3、MinIO)或HDFS。
- 数据分析平台集成:可以将Elasticsearch中的数据通过Logstash或Spark等工具,同步到数据仓库(如Hive)或数据分析平台进行更深度的离线分析和报表生成。
- 安全与权限:通过Elasticsearch的安全特性(如X-Pack)或外部代理,实现基于角色的访问控制(RBAC),确保日志数据的安全。
****
从本地开发的GC日志微观分析,到生产环境TB级日志的宏观监控,体现了软件生命周期中不同阶段的性能治理需求。本地GC调优是提升单应用性能的基础,而ELK为核心的日志监控系统则是保障大规模分布式系统可观测性的基石。通过合理的架构设计、组件配置和优化策略,ELK能够稳定高效地处理海量日志,为故障排查、性能分析和业务洞察提供强大的数据支持。在实际搭建时,建议从小规模开始,随着数据量和需求的增长,逐步迭代架构,引入消息队列、集群化和分层存储等高级特性。