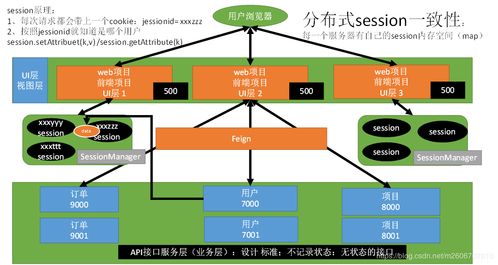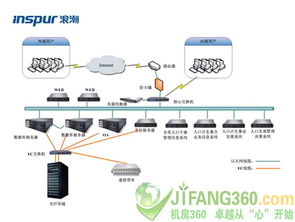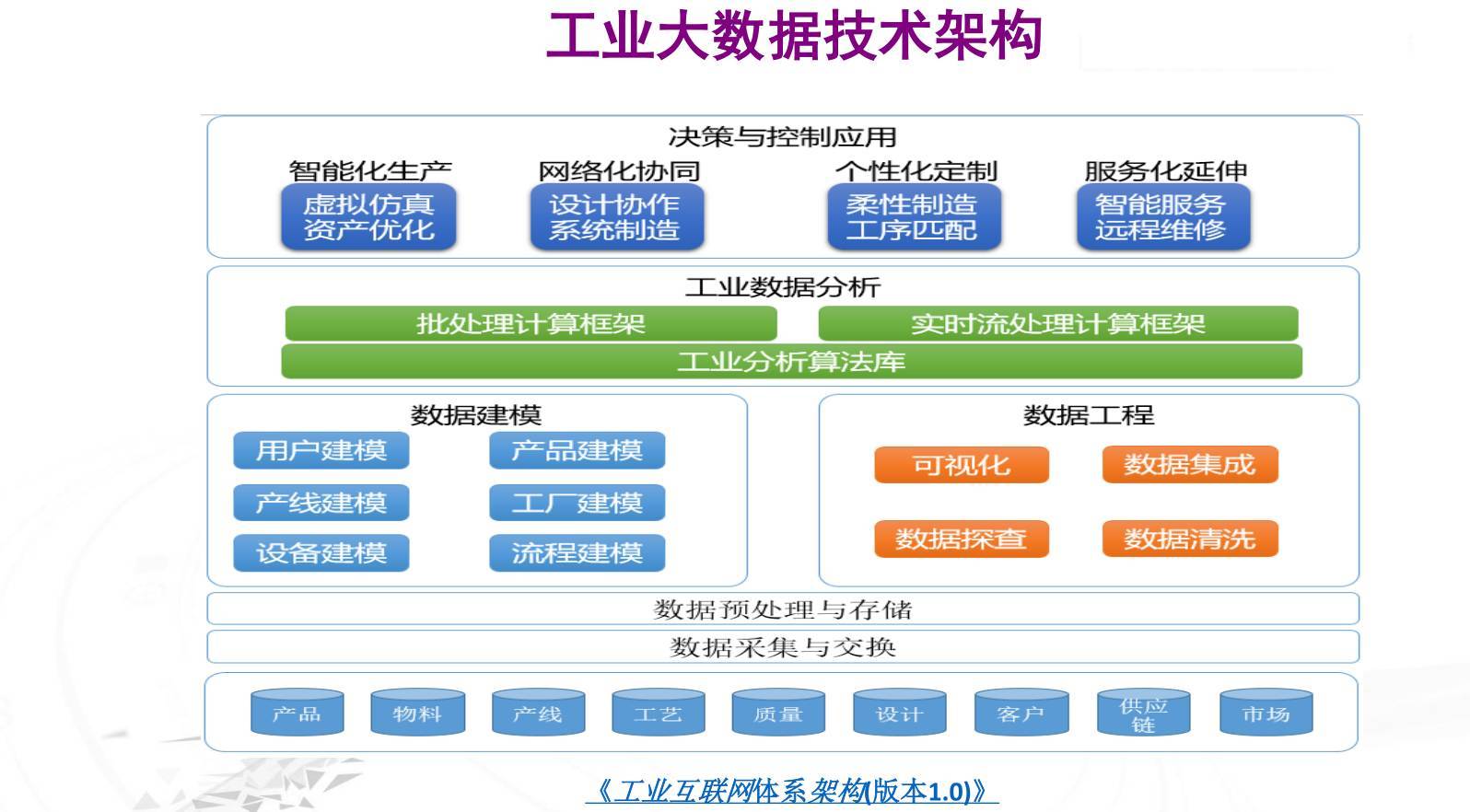
在智能制造领域,机器学习(ML)正成为提升生产效率、优化质量控制、实现预测性维护的关键驱动力。从原始数据到可部署的智能模型,这一过程并非一蹴而就,其核心在于构建一个高效、可靠的数据处理和存储服务流程。本文将深入探讨智能制造场景下快速实现机器学习所依赖的核心数据处理与存储流程。
一、数据采集与汇聚:智能制造的感知基石
智能制造环境中的数据来源极其广泛,包括:
- 设备层数据:来自数控机床、机器人、传感器(如温度、压力、振动)的实时运行参数与状态日志。
- 生产层数据:制造执行系统(MES)中的工单、物料、工艺参数和质量检测结果。
- 企业层数据:来自ERP系统的订单、供应链及库存信息。
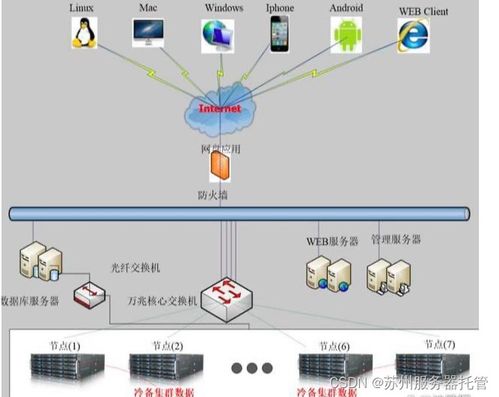
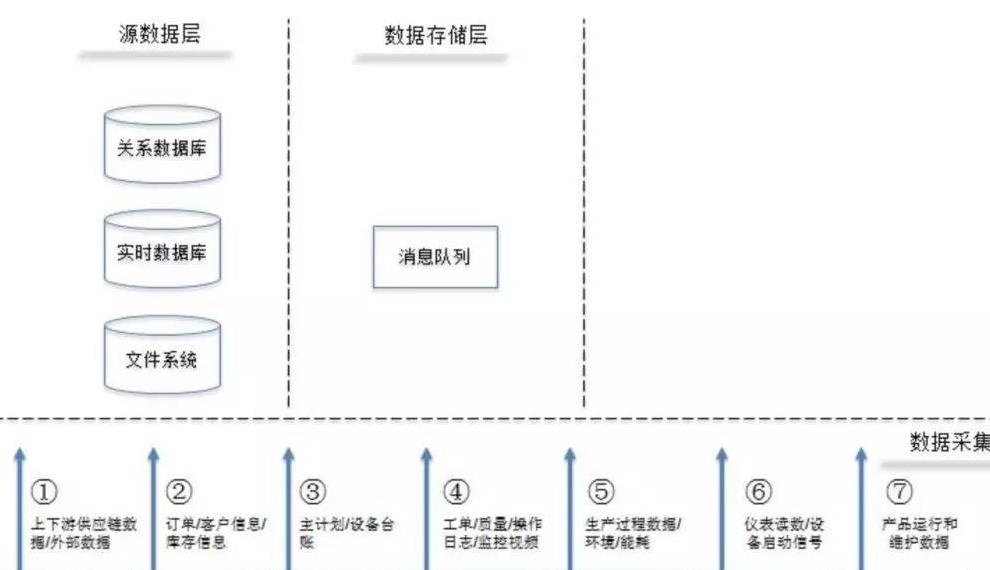
核心流程:通过工业物联网(IIoT)网关、边缘计算设备或直接API接口,将多源、异构的实时流数据与批量历史数据汇聚到统一的数据接入层。此阶段需确保数据的实时性、完整性与初步的时序对齐。
二、数据预处理与特征工程:从原始数据到模型“燃料”
原始工业数据通常含有噪声、缺失值和不一致问题,直接用于模型训练效果甚微。
- 数据清洗:处理异常值(如传感器故障导致的尖峰)、填充缺失值(采用前后插值或基于业务逻辑的填充)、纠正格式错误。
- 数据转换与标准化:将不同量纲和范围的数据(如转速与温度)进行归一化或标准化,使模型更容易收敛。对于时序数据,常需进行重采样以统一频率。
- 特征工程:这是提升模型性能的关键。在智能制造中,特征常从时序数据中提取,例如:
- 统计特征:均值、方差、峰值、峭度。
- 时域/频域特征:通过傅里叶变换提取频谱特征,用于振动分析。
- 领域特征:基于工艺知识的特定组合指标(如设备综合效率OEE的构成因子)。
三、数据存储与管理:构建可靠的数据湖/仓
为支持机器学习不同阶段(探索、训练、推理)的需求,需要分层、弹性的存储架构。
- 原始数据存储区(数据湖):使用如Hadoop HDFS、云对象存储(如AWS S3, Azure Blob)低成本存储汇聚而来的原始数据,保留最大粒度信息以备后续深度挖掘。
- 处理与特征存储区:存储清洗后、标注好的数据集以及生成的特征表。采用列式存储(如Apache Parquet)或特征存储数据库,便于高效查询和批量读取,供模型训练使用。
- 元数据与版本管理:记录数据来源、处理流水线、特征定义及数据集版本,确保实验的可复现性。工具如MLflow、DVC在此环节至关重要。
- 实时数据管道:对于需要在线学习或实时预测的场景,需构建基于Kafka、Pulsar等流处理平台的数据管道,将处理后的特征低延迟地输送给在线模型服务。
四、核心支撑服务:实现流程自动化与加速
要“快速”实现机器学习,必须将以上流程服务化、自动化。
- 可复用的数据处理流水线:使用Apache Airflow、Kubeflow Pipelines等工具将数据采集、清洗、特征提取等步骤编排成自动化工作流,确保数据的一致性和生产化。
- 特征平台:构建中心化的特征存储和计算服务,实现特征的定义一次、多处复用,避免训练与推理服务的特征不一致问题。
- 数据质量监控:持续监控数据流的完整性、新鲜度和统计分布。一旦发现数据漂移(如传感器精度下降导致的数据分布变化),能及时告警,因为数据漂移是导致模型性能衰减的主要原因之一。
五、与模型生命周期的闭环集成
数据处理与存储并非孤立环节,它与模型开发、部署、监控紧密相连。
- 训练阶段:从特征存储中快速抽取一致、版本化的训练数据集。
- 部署与推理阶段:在线服务从特征管道或特征库中实时获取预处理后的特征,进行预测。
- 监控与迭代阶段:持续收集模型预测结果与实际反馈(如预测性维护是否准确),并将这些新数据回流至数据湖,形成“数据->模型->应用->新数据”的增强闭环,驱动模型持续优化。
结论
在智能制造中,机器学习价值的快速兑现,高度依赖于一个坚实、敏捷的数据处理与存储服务基础架构。这一核心流程将混乱的原始工业数据转化为高质量、可追溯、易获取的“模型就绪”数据,并确保其在生产环境中持续、可靠地流动。企业只有系统化地构建并优化这一数据基石,才能让机器学习真正融入智能制造的血液,实现从“制造”到“智造”的跨越。