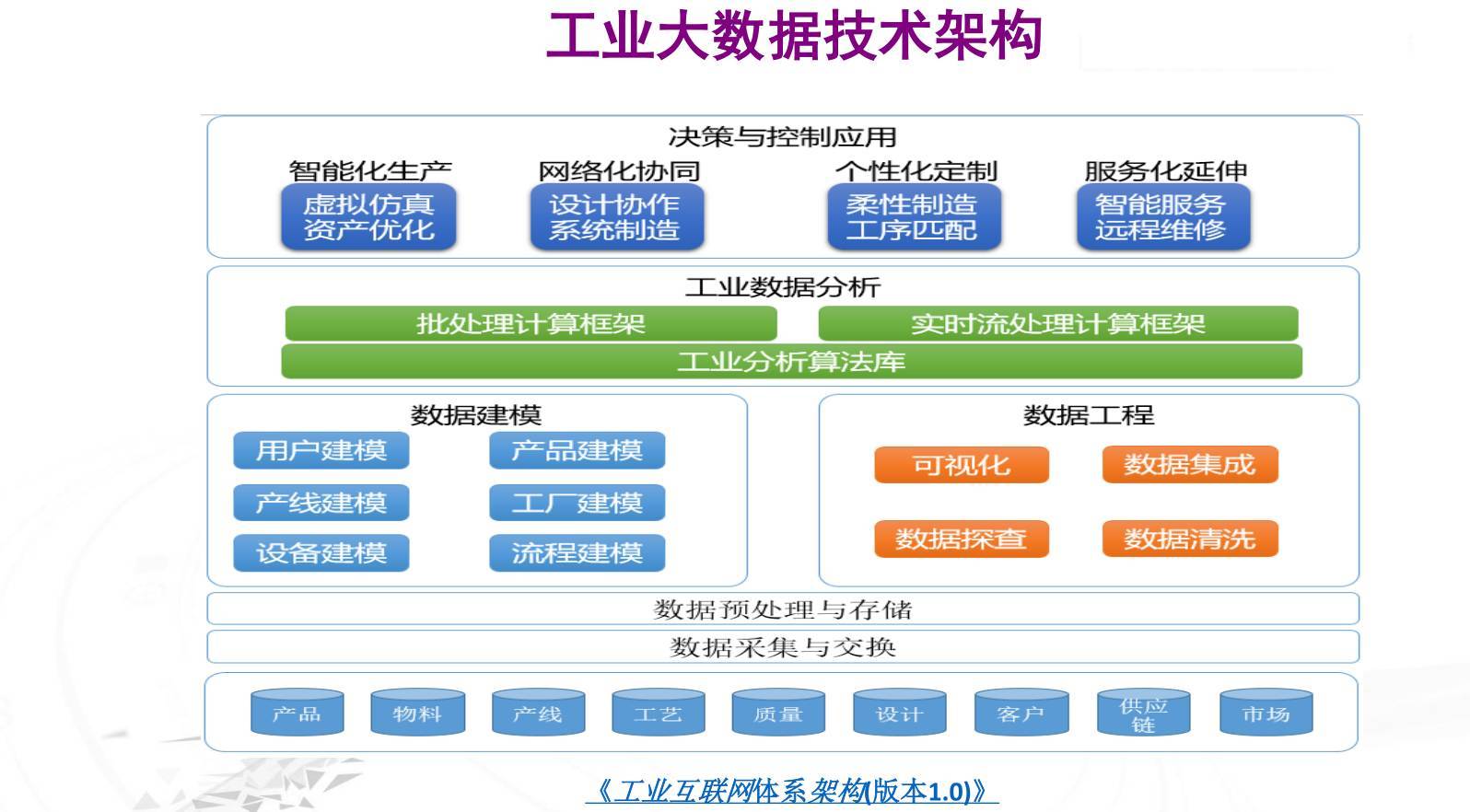
在大数据时代,企业面临着海量数据的处理与存储挑战。传统的关系型数据库虽然在结构化数据处理上表现出色,但在应对非结构化、半结构化数据以及PB级别的数据规模时,显得力不从心。正是在这样的背景下,Apache Hive应运而生,成为了大数据生态系统中的重要一环。
Hive的引入背景可以追溯到Facebook的数据处理需求。早期,Facebook的数据团队需要处理和分析海量的用户日志数据,这些数据通常以文本文件的形式存储在Hadoop分布式文件系统(HDFS)中。尽管Hadoop的MapReduce框架提供了强大的批处理能力,但其编程模型相对复杂,需要开发人员编写大量的Java代码,这对于数据分析师和业务人员来说门槛较高。为了解决这一问题,Facebook的工程师团队开发了Hive,旨在通过类SQL的查询语言(HiveQL)来简化大数据查询与分析。
作为数据处理服务,Hive的核心优势在于其将SQL-like查询转换为MapReduce任务的能力。用户只需编写熟悉的SQL语句,Hive便会自动将其编译成一系列MapReduce作业,在Hadoop集群上执行。这大大降低了大数据处理的技术门槛,使得数据分析师、业务人员甚至非技术人员都能轻松进行数据查询与分析。Hive支持用户自定义函数(UDF),允许用户扩展功能以满足特定需求,进一步增强了其灵活性和实用性。
在数据存储服务方面,Hive提供了表的概念,允许用户将HDFS上的数据文件组织成结构化的表。这些表可以分区、分桶,以优化查询性能。Hive支持多种存储格式,如文本文件、序列文件、ORC、Parquet等,用户可以根据数据特点和查询需求选择最合适的格式。例如,列式存储格式(如ORC、Parquet)特别适用于分析型查询,因为它们可以显著减少I/O操作,提升查询速度。Hive还支持数据压缩,有效降低了存储成本。
Hive的元数据存储在关系型数据库(如MySQL、PostgreSQL)中,这使得表结构、分区信息等元数据可以独立于HDFS进行管理,提高了元数据的可靠性和可访问性。通过Hive的元数据服务,用户可以直接查询表结构、查看分区信息,而无需直接操作HDFS文件。
随着技术的发展,Hive也在不断演进。例如,Hive on Tez和Hive on Spark等执行引擎的引入,显著提升了查询性能,使得Hive能够更好地应对实时或近实时的数据处理需求。Hive与Hadoop生态系统中其他组件(如HBase、Spark、Flink)的集成,进一步扩展了其应用场景。
Hive的引入不仅简化了大数据处理流程,还为企业提供了一种高效、灵活的数据存储解决方案。无论是作为数据仓库的基础设施,还是作为数据分析的平台,Hive都在大数据领域扮演着不可或缺的角色。随着技术的进步,Hive将继续演化,为用户带来更强大的数据处理与存储能力。