在上一篇文章中,我们介绍了线性表的基本概念和顺序存储实现。本文将继续深入,讲解如何使用C语言的链式存储(链表)来实现线性表,并探讨其在数据处理和存储服务中的应用。链表是一种动态数据结构,能够更灵活地管理内存,适用于频繁插入和删除操作的场景。
一、链式存储的基本概念
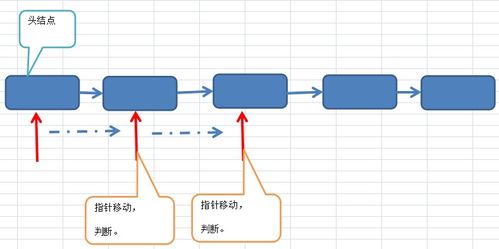
链式存储通过节点来存储数据元素,每个节点包含数据域和指针域。数据域存储实际的数据,指针域存储下一个节点的地址。这种结构使得数据元素在内存中不必连续存放,从而提高了存储的灵活性。
链表主要分为单链表、双链表和循环链表等类型。本文将以单链表为例,详细讲解其实现过程。
二、单链表的C语言实现
1. 定义链表节点结构
我们需要定义链表节点的结构体。每个节点包含一个整型数据(可根据需求修改)和一个指向下一个节点的指针。
typedef struct Node {
int data; // 数据域
struct Node* next; // 指针域,指向下一个节点
} Node;2. 初始化链表
初始化链表即创建一个头节点。头节点不存储实际数据,仅用于标识链表的起始位置。
Node* initList() {
Node head = (Node)malloc(sizeof(Node)); // 分配内存
if (head == NULL) {
printf("内存分配失败!\n");
exit(1);
}
head->next = NULL; // 头节点的指针域为空
return head;
}3. 插入操作
在链表中插入节点分为头插法和尾插法。这里以尾插法为例,在链表末尾插入新节点。
`c
void insertAtEnd(Node* head, int value) {
Node newNode = (Node)malloc(sizeof(Node));
if (newNode == NULL) {
printf("内存分配失败!\n");
return;
}
newNode->data = value;
newNode->next = NULL;
Node* current = head;
while (current->next != NULL) {
current = current->next;
}
current->next = newNode;
}`
4. 删除操作
删除操作需要找到待删除节点的前驱节点,修改其指针域以跳过待删除节点,并释放内存。
void deleteNode(Node* head, int value) {
Node* current = head;
while (current->next != NULL && current->next->data != value) {
current = current->next;
}
if (current->next == NULL) {
printf("未找到值为 %d 的节点。\n", value);
return;
}
Node* temp = current->next;
current->next = temp->next;
free(temp);
}5. 查找操作
遍历链表,查找指定值的节点。
Node searchNode(Node head, int value) {
Node* current = head->next; // 跳过头节点
while (current != NULL) {
if (current->data == value) {
return current;
}
current = current->next;
}
return NULL; // 未找到
}6. 遍历链表
遍历链表并打印每个节点的数据。
void traverseList(Node* head) {
Node* current = head->next;
if (current == NULL) {
printf("链表为空。\n");
return;
}
printf("链表元素:");
while (current != NULL) {
printf("%d ", current->data);
current = current->next;
}
printf("\n");
}7. 释放链表内存
使用完链表后,需要释放所有节点占用的内存,避免内存泄漏。
void freeList(Node* head) {
Node* current = head;
while (current != NULL) {
Node* temp = current;
current = current->next;
free(temp);
}
}三、数据处理与存储服务中的应用
链表在数据处理和存储服务中有着广泛的应用,主要体现在以下几个方面:
1. 动态数据管理
链表允许动态分配内存,适合处理数据量不确定或频繁变化的场景。例如,在实时数据采集系统中,新数据不断产生,链表可以方便地插入新节点,而无需像数组那样预先分配固定大小的内存。
2. 高效插入与删除
在存储服务中,经常需要进行数据的增删改查。链表在插入和删除操作上具有优势,时间复杂度为O(1)(已知位置)或O(n)(需查找位置),相比顺序存储的O(n)移动操作,效率更高。
3. 实现其他数据结构
链表是许多高级数据结构的基础,如栈、队列、图等。在数据处理服务中,这些数据结构常用于任务调度、缓存管理、网络通信等场景。
4. 内存优化
链表可以更灵活地利用内存碎片,适合在内存受限的嵌入式系统或大规模分布式存储系统中使用。例如,在文件系统的块管理中,链表可用于维护空闲块列表。
四、实例:使用链表管理用户数据
假设我们需要开发一个简单的用户管理系统,使用链表来存储用户ID。以下是一个简化的示例:
`c
#include #include
// 链表节点定义和上述函数实现...
int main() {
Node* userList = initList(); // 初始化用户链表
// 插入用户ID
insertAtEnd(userList, 1001);
insertAtEnd(userList, 1002);
insertAtEnd(userList, 1003);
traverseList(userList); // 输出:链表元素:1001 1002 1003
// 删除用户ID
deleteNode(userList, 1002);
traverseList(userList); // 输出:链表元素:1001 1003
// 查找用户ID
Node* result = searchNode(userList, 1003);
if (result != NULL) {
printf("找到用户ID:%d\n", result->data);
}
freeList(userList); // 释放内存
return 0;
}`
五、
本文详细介绍了如何使用C语言通过链式存储实现线性表,包括节点的定义、初始化、插入、删除、查找和遍历等基本操作。链表作为一种动态数据结构,在数据处理和存储服务中具有重要应用,能够高效管理动态数据,支持频繁的插入和删除操作,并为实现更复杂的数据结构奠定基础。
在实际开发中,根据具体需求选择合适的链表类型(如双链表或循环链表),并注意内存管理,避免内存泄漏。通过不断练习和实践,您将能够熟练掌握链表的应用,提升数据处理和存储服务的开发能力。